

The Problem
JSTOR is a growing digital library of more than 2,000 academic journals, 8 million digitized articles, 2 million primary source documents, and an overall 46 million pages of content. College students and independent researchers worldwide rely on its archives to get their work done.
When JSTOR decided to expand its offerings to include 20,000 e-books, the business needed had to understand the academic e-book landscape and what researchers needed from e-books - fast. The e-book content needed to be integrated and surfaced in a way that would be optimally helpful for our users.
Below: Search results page, before and after.
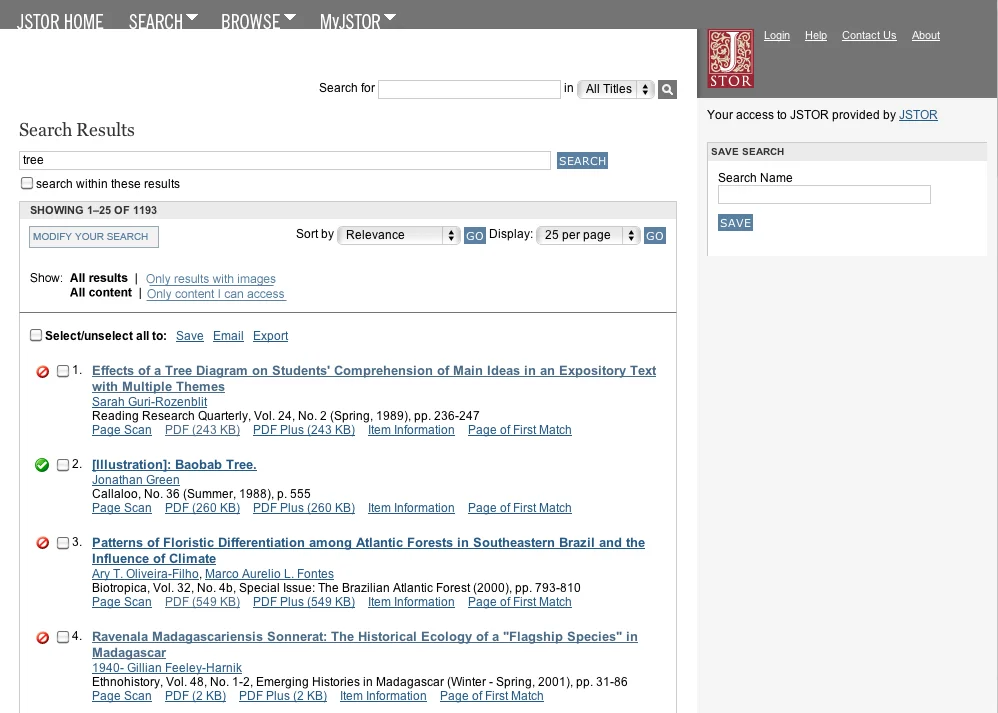

The Solution
I conducted research into what students needed from different content types, worked with product managers to synthesize requirements, and put together designs that successfully integrated all of JSTOR's diverse content into one search platform.
The Process
The JSTOR platform had always served other types of content, such as articles, that were fundamentally different, so we needed to round out our understanding of how students do research. Because e-books have different kinds of content, are structured differently, and are used for research differently, our users had different workflows and thus different feature requirements that would be connected in different ways.
First, understand the user. How do e-books fit into their overall research patterns? To answer this, I conducted research interviews contextual inquiry with 7 students to understand their current e-book usage, going to their usual work spots (graduate student corrals, offices, and the library) to observe as they worked.
I communicated findings through several channels, tailoring to my audience (reports for those who like to read, presentations for those who like to listen, and synthesis posters to provide an actionable summary. This is is a hybrid journey map / mental model for Cynthia, JSTOR's graduate student persona. Here, I show her overall research workflow for books, and how specific features and metadata could serve those needs. This kind of information helped the product manager to weigh and prioritize features throughout the build.

Next, understand and anticipate the user's problems. Scholarly e-books very new at the time, and very few platforms were working with it as a content type, so I conducted usability testing with 9 undergraduate and graduate students on an existing e-book platform to see what problems we could anticipate within the context of scholarly research. Below is a sample finding.

As a result of this study, we decided to give students tools to evaluate the book's quality and relevance from search results (is it from a good publisher? good author? does it cover the right topics?). Design recommendations to address this included easy-to-access metadata, book previews and visual indicators for which chapters their search terms are in.
Another problem that came up: only a specific number of e-books can be in use at a given time. My research showed thatstudents often have projects on similar topics at similar times (the Medieval History final paper, for example). If someone doesn't end up needing the book, better to let them find out sooner rather than going through the workflow and also tying up a resource that someone else could use. Below: Some recommendations to address this.

Below is a screenshot of a JSTOR eBook in the wild. This book is open access and can be explored here: https://www.jstor.org/stable/j.ctt24h7w1

Another problem the research surfaced was the search filtering experience. Searching is at the core of JSTOR's platform, connecting users to those millions and millions of resources. If they can't find something, they can't use it.

Excerpt from the findings document.
We found that e-book search presented unique difficulties to JSTOR's algorithm. For example, a keyword might show up 15 times in a 200-page e-book, but 10 times in a 20-page journal article; the difference in hit density means that e-books would quite often be buried in the search results. We tweaked the algorithm to account for this, and I also took a first pass at the filtering design, trying to find ways to help users easily switch content types and also understand when they may be missingout.


The project also had technical constraints. For example, JSTOR's architecture didn't allow performance-friendly dynamic filtering. I settled on a design that allowed students to work with their filters and then submit all their changes as a single query, which is how it works today.
